 DriveQA: Passing the Driving Knowledge Test
DriveQA: Passing the Driving Knowledge Test
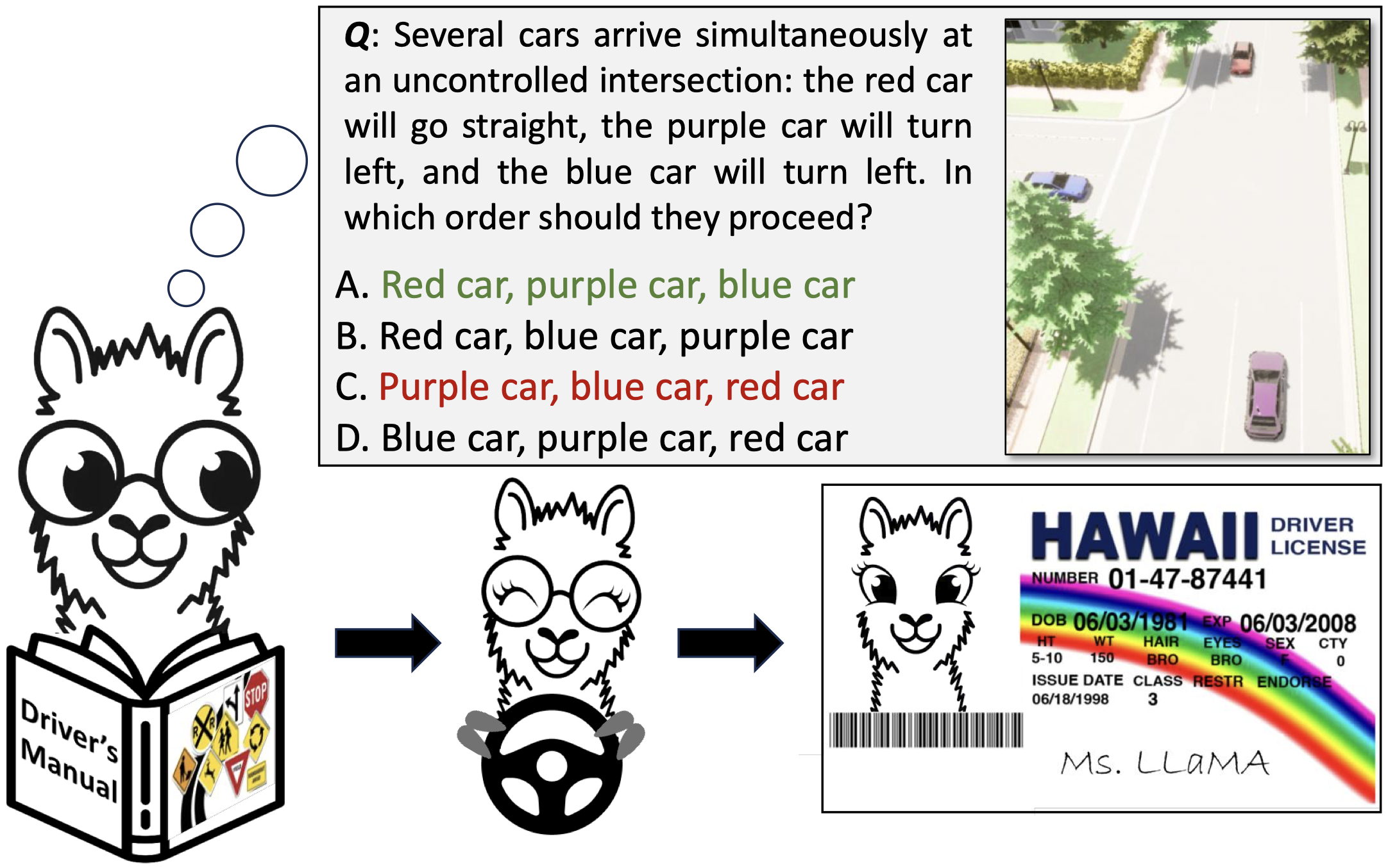
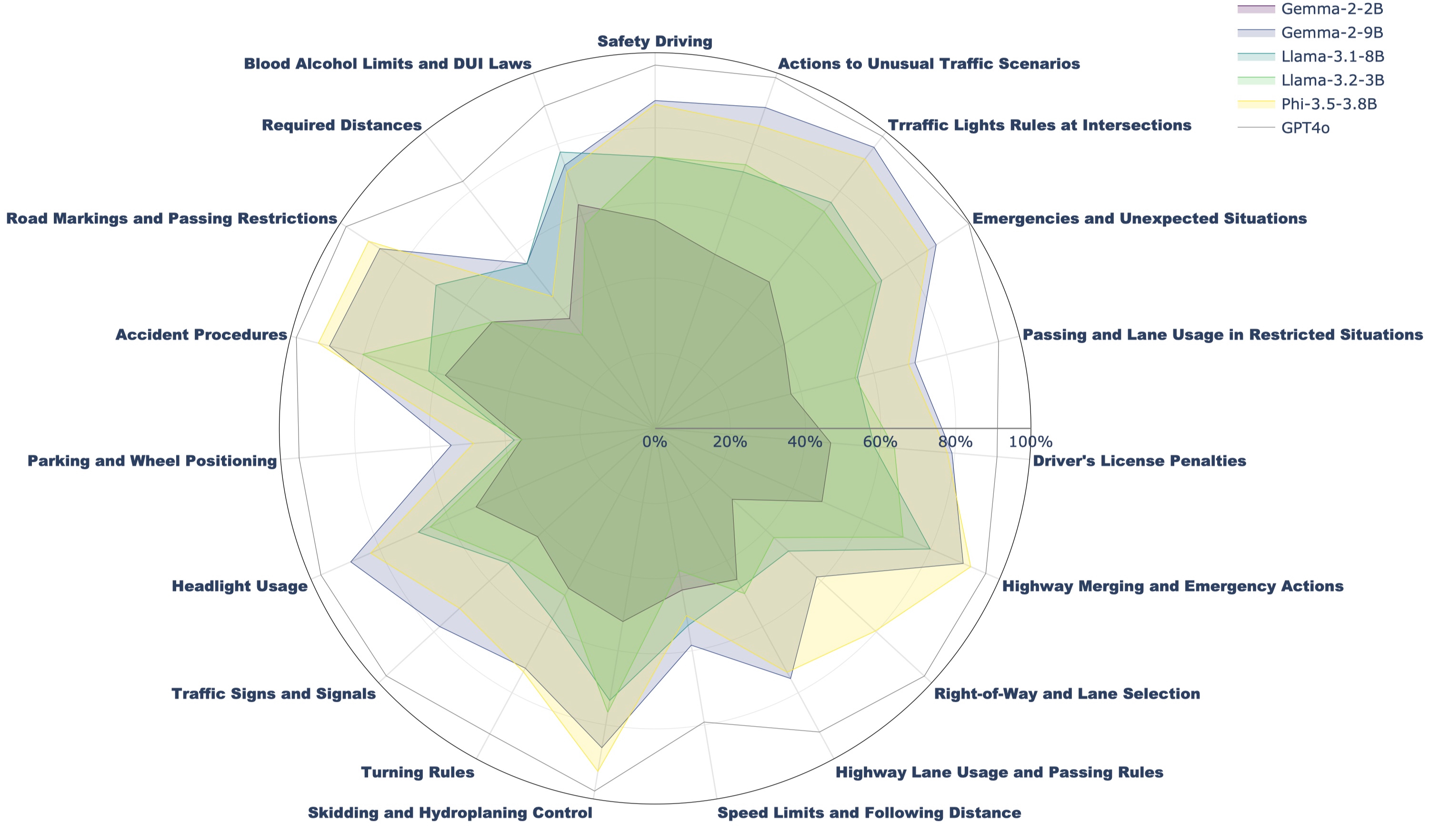
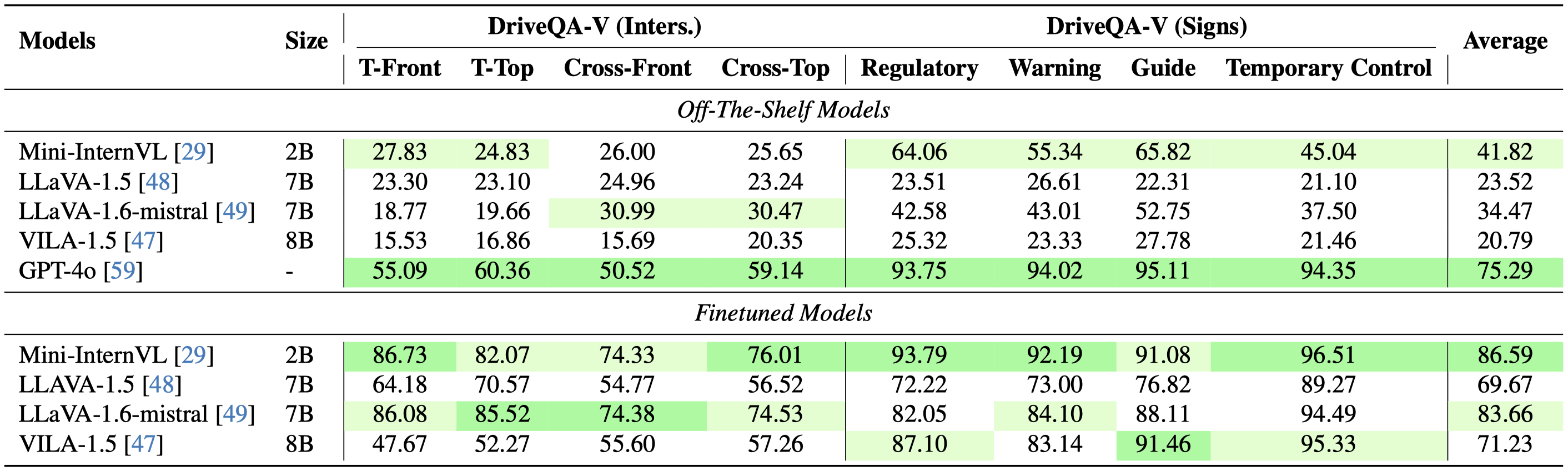
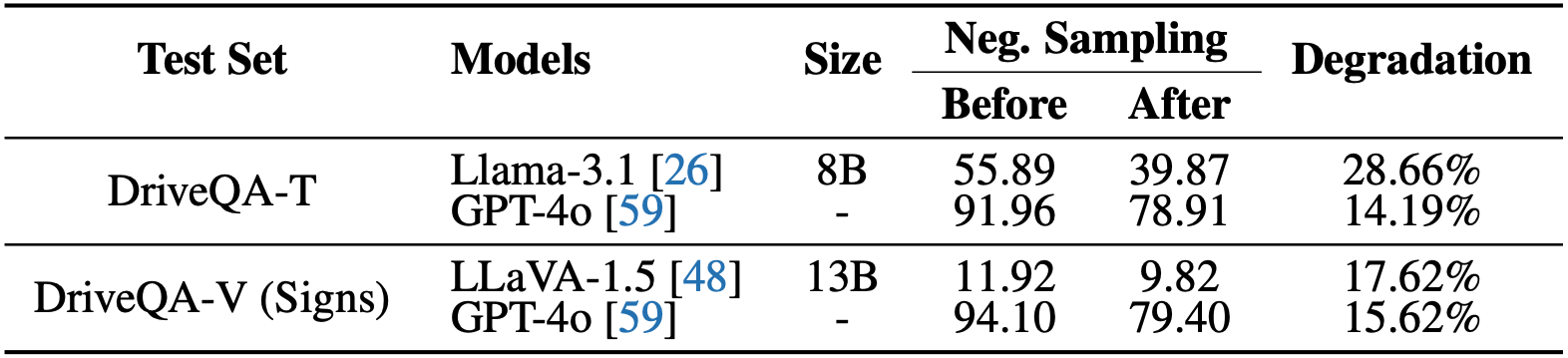
If a Large Language Model (LLM) were to take a driving knowledge test today, would it pass? Beyond standard spatial and visual question-answering (QA) tasks on current autonomous driving benchmarks, driving knowledge tests require a complete understanding of all traffic rules, signage, and right-of-way principles. To pass this test, human drivers must discern various edge cases that rarely appear in real-world datasets. In this work, we present DriveQA, an extensive open-source text and vision-based benchmark that exhaustively covers traffic regulations and scenarios. Through our experiments using DriveQA, we show that (1) state-of-the-art LLMs and Multimodal LLMs (MLLMs) perform well on basic traffic rules but exhibit significant weaknesses in numerical reasoning and complex right-of-way scenarios, traffic sign variations, and spatial layouts, (2) fine-tuning on DriveQA improves accuracy across multiple categories, particularly in regulatory sign recognition and intersection decision-making, (3) controlled variations in DriveQA-V provide insights into model sensitivity to environmental factors such as lighting, perspective, distance, and weather conditions, and (4) pretraining on DriveQA enhances downstream driving task performance, leading to improved results on real-world datasets such as nuScenes and BDD, while also demonstrating that models can internalize text and synthetic traffic knowledge to generalize effectively across downstream QA tasks.
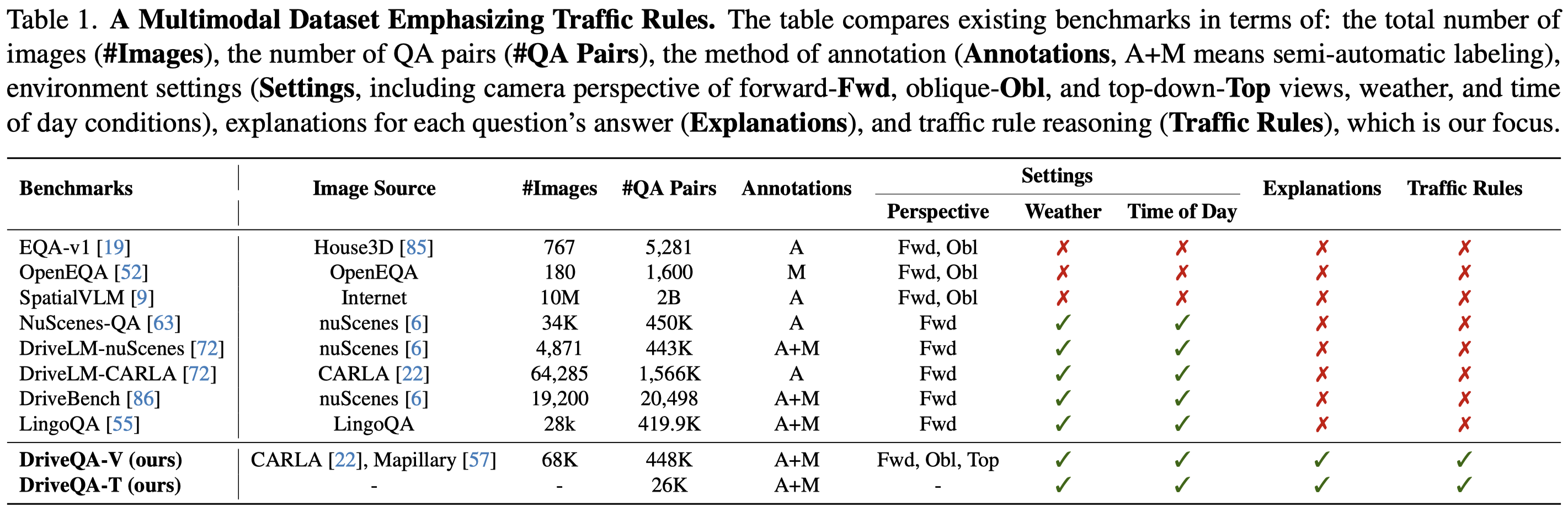
474K QA pairs
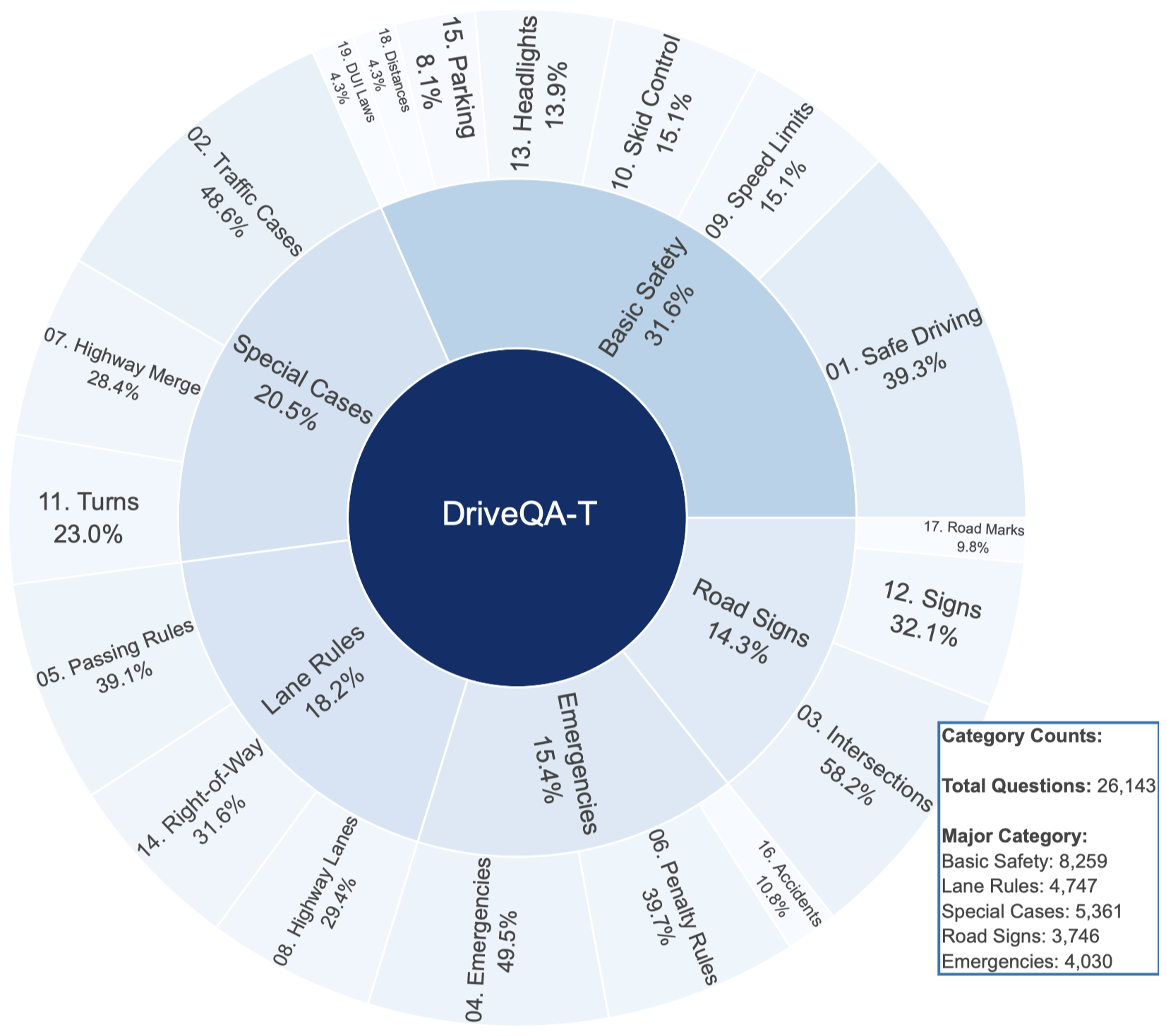
26K text-based questions
448K vision-based tasks
220 traffic sign types
19 question categories
Controlled variations
Explanations included
Real + synthetic data
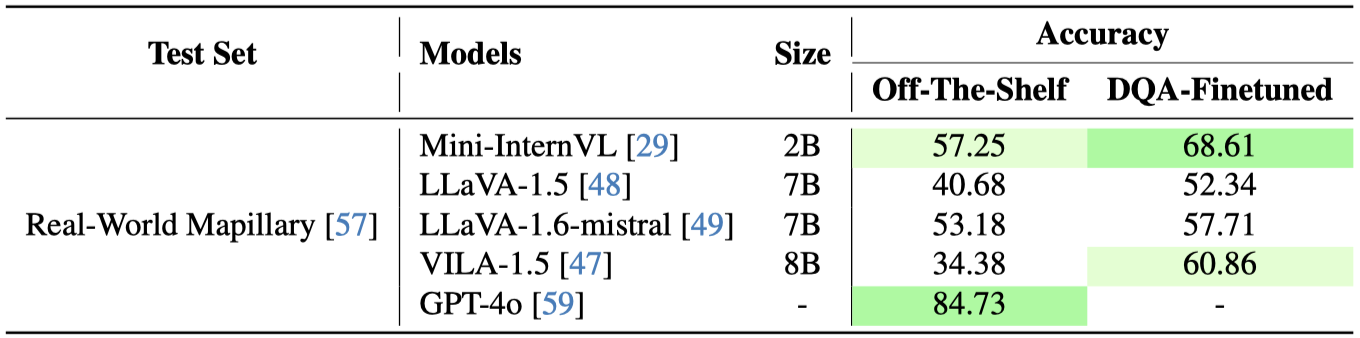
Improved nuScenes performance
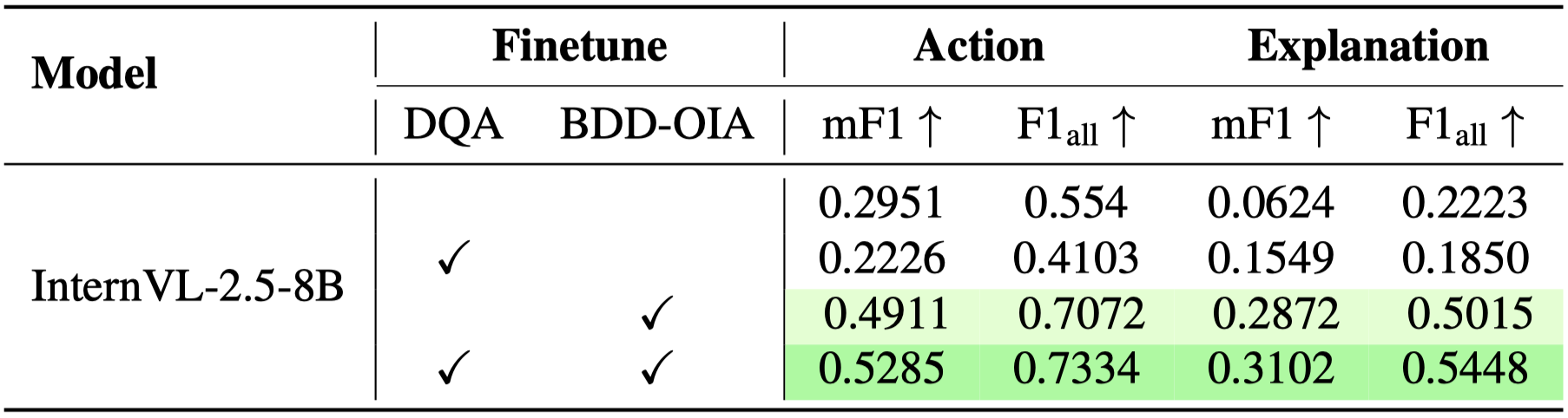
Better BDD-OIA results
Sim-to-real generalization
Downstream task gains

@inproceedings{wei2025driveqa,
title={Passing the Driving Knowledge Test},
author={Wei, Maolin and Liu, Wanzhou and Ohn-Bar, Eshed},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2025}
}Please cite DriveQA if you find it helpful!
